基础
数据类型
基本类型:boolean、byte、short、char、int、float、double、long
引用类型:数组、String、对象
基本类型值就直接保存在变量中,引用类型保存实际对象的地址
十进制负数是以补码的形式存储在内存中的,而十六进制负数是以原码的形式存储在内存中的,并且最高位是符号位,后面的31位为序号位,不是值位
MIN_VALUE = 0x80000000(原码)
MAX_VALUE = 0x7fffffff
值传递、引用传递
使用=,基本类型直接覆盖,引用类型地址被覆盖,但是原来的对象不会改变
Queue
LinkList实现
- poll 删除首部
- offer 添加到尾部
Stack
new Stack();
- push
- pop
集合
java中的集合专门用来存储对象(对象的引用),这些对象可以是任意的数据类型,且长度可变
Collection接口
单列集合的根接口
add(); // 尾部添加
addAll();
clear(); // 清空
remove(); // 修改
removeAll( Collection c ); // 删除其中的c
isEmpty();
contains( Object obj );
containsAll( Collection c );
iterator();
stream(); // 转换为流List
- 有序(存入和取出顺序一致),可重复
- ArrayList、LinkedList
add(index, obj);
add(index, collection )
get(index);
remove(index);
set(index, obj);
indexOf(obj); // 查看下标
lastIndexOf(obj); // 最后出现的
subList(startIndex, toIndex); // 组合出新集合
toArray();
sort(Comparator)ArrayList
封装了长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组对象来存储这些元素
优点:查询速度快
缺点:在增加或删除指定位置的元素时,会创建新的数组,效率比较低,不适合做大量的增删操作
arr、List转换
// 数组和List转换
int[] arr = {1,2,3};
Integer[] integerArr = {1,2,3};
// arr -> list
List<Integer> iList = new ArrayList<>(Arrays.asList(integerArr));
List<Integer> integerList = Arrays.stream(arr).boxed().collect(Collectors.toList());
// list - > arr
Integer[] integers = iList.toArray(new Integer[0]);
int[] ints = integerList.stream().mapToInt(Integer::intValue).toArray();
LinkedList
内部有两个Node类型的first和last属性维护一个双向循环链表
当做栈
push(Object o); // 添加到栈顶
pop(); // 移除返回栈顶当做队列
add(); // 加入队尾
addAll();
getFirst(); // 获取第一个元素
removeFirst(); // 移除获取队首转Map
Map<String, String> map = list.stream().collect(Collectors.toMap(Person::getId, Person::getName);Set
- 无序,不可重复
- HashSet、TreeSet
HashSet
根据hash值确定元素的出处位置,因此具有良好的存取和查找性能
判断是否重复:
- hashCode()确定存储位置
- 元素的equals()确认不重复
TreeSet
以二叉树来存储元素,可以实现对集合中的元素进行排序
存储元素
- 与顶层元素比较大小
- 小于,往左
- 大于,往右
- 等于,结束
- 循环
重写
compareTo
自然排序
this为要插入的,大于1在右边
// 类实现comparable接口
class Teacher implements comparable {
// 先比较年龄再比较名字
public int compareTo(Object obj) {
Teacher teacher = (Teacher) obj;
if( this.age - teacher.age > 0) { // this为待排序的元素,teacher为树中的元素
return 1; // 往右
}
if( this.age - s.age == 0 ) {
return this.name.compareTo(teacher.name); // String实现了comparable接口
}
return -1; // 往左
}
}定制排序
要插入的,原来的,大于1在右边
// 1. 抽离实现comparator接口
class MyComparator implements Comparetor {
public int compare( Object obj1, Object obj2 ) { // 要插入的, 原来的
String s1 = String obj1;
String s2 = String obj2;
return s1.length() - s2.length(); // 从小到大
}
}
new TreeSet( new MyComparator() );
// 2.使用lambda实现
new TreeSet( (obj1, obj2) -> {
String s1 = String obj1;
String s2 = String obj2;
return s1.length() - s2.length();
} );方法
lower( Object o ); // 小于的最大,否则null
floor( Object o ); // 小于或等于的最大
heiger( Object o ); // 大于的最小
ceiling( Object o ); // 大于或等于的最小遍历
Iterator
不能使用list的remove方法,迭代次数会改变,可以使用迭代器本身的remove方法
Iterator iterator = list.iterator();
while( iterator.hasNext() ) {
Object obj = iterator.next();
}
// 使用1.8的forEach
it.forEachRemaining( obj -> {
})foreach
不能对元素进行修改
for( Object tempObject : foreachObject ) {
}forEach遍历集合
1.8有的
list.forEach( obj -> {
});Map
key不重复
方法
put() putIfAbsent() 如果已经存在,则不添加并返回存在的值
remove() size()
replace( Object key, Object value)
get() getOrDefault( Object obj, default )
containsKey() containsValue()
HashMap
键不能重复,元素无序
底层:哈希表结构组成,数组 +链表,数组是主体,链表用于解决哈希值冲突而存在的分支结构
哈希表结构:
- 水平方向数组长度成为HashMap集合的容量
- 垂直方向每个元素位置对应链表结构称为一个桶,每个桶的位置在集合中都有对应的桶值,用于快速添加、查找时的位置
存入过程:
- 计算对象hash,确定存储桶的位置
- 桶中为空,存入
- 桶中没有重复键,插入
- 桶中有重复键,替换并返回原值
好处:增删改查效率都比较高
桶的数目(数组长度)越多越好,能够hash后直接插入,否则需要遍历桶中的链表,确认无重复键
动态分配桶的数量
new时,默认容量为16,加载因子loadFactor为0.75,此时集合桶的阈值就为12(16*0.75),当存储超过12个元素,HashMap默认增加一倍桶的数量
如果对存储效率不高,想节省空间,可以用new HashMap( int initialCapacity, float loadFactory )进行设置
遍历
使用Iterator
// 1.
Set keySet = map.keySet(); // 获取key集合
Iterator it = keySet.iterator();
while( it.hasNext() ) {
Object key = it.next(); // 获取键
Object value = map.get(key); // 获取值
}
// 2.
Set entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while( it.hasNext() ) {
Map.Entry entry = ( Map.Entry ) ( it.next() ); // 获取键值映射关系
Object key = entry.getKey();
Object value = entry.getValue();
}
使用foreach
map.forEach( (key, value) -> {
});Collection value = map.values();
value.forEach( value -> {
})LinkedHashMap
能保证存入和取出(遍历)的顺序
TreeMap
排序
// 1. 抽离实现comparator接口
class MyComparator implements Comparetor {
public int compare( Object obj1, Object obj2 ) { // 要插入的, 原来的
String s1 = String obj1;
String s2 = String obj2;
return s1.length() - s2.length(); // 从小到大
}
}
new TreeMap( new MyComparator() );
// 2.使用lambda实现
new TreeMap( (obj1, obj2) -> {
String s1 = String obj1;
String s2 = String obj2;
return s1.length() - s2.length();
} );Properties
Hashtable是线程安全的,效率不及HashMap
Hashtable子类Properties主要用来存储字符串类型的键和值
color=read
language=chineseProperties properties = new Properties();
// 1.读取
propertise.load( new FileInputStream("test.properties") ); // 读取文件
pps.forEach( (k, v) -> {
});
// 2.写入
FileOutputStream out = new FileOutputStream("test.properties");
properties.setProperty("charset", "UTF-8");
pps.store(out, "新增charset编码"); // 写入,并添加注释?工具类
Collections工具类
添加、排序
boolean addAll(collection, ...elements); // 添加到集合中
reverse(list); // 翻转
shuffle(list); // 打乱
sort(list); // 排序
swap(list, int i, int j); // 下标i j交换查找、替换
binarySearch(list, obj); // 二分查找 有序集合 值的下标
max(collection); // 排序,返回最大
min(collection); // 返回最小
replaceAll(list, oldVal, newVal)Arrays工具类
Arrays.sort();
Arrays.binarySearch(arr, 3);
Arrays.copyOfRange(originalArr, from, to); // 不包括to
Arrays.fill(objectArr, 8); // 全部填充为8栈、队列
Stack s = new Stack<Integer>();
s.push();
s.pop();
s.peek(); // 查看第一个
Queue<Integer> q = new LinkedList<>();
// add remove 失败会抛出异常
q.offer(1); // 添加
q.poll(); // 取出第一个
q.peek(); // 查看第一个
Deque<Integer> q = new LinkedList<>();
q.offerFirst/last(1); // 添加
q.pollFirst/Last(); // 取出第一个
q.peekFirst/Last(); // 查看第一个
new LinkedList<Integer>(q);IO操作
File、InputStream、OutputStream、Reader、Wirter

File
文件的类型、创建、删除、重命名、取得文件大小、修改日期
// new, 文件系统分隔符:File.separator
new File(String pathname);
/* ---- 基础操作 ----- */
// 存在?
file.exists();
// 创建 文件
public boolean createNewFile() throws IOException;
// 创建 目录
public boolean mkdirs();
// 删除
public boolean delete();
// 父文件
file.getParentFile();
/* ------ 文件信息 ------*/
// 给定的路径是否是文件夹
public boolean isDirectory();
// 给定的路径是否是文件
public boolean isFile();
// 是否是隐藏文件
public boolean isHidden();
// 文件的最后一次修改日期
public long lastModified();
// 文件长度,字节为单位
public long length();
字节流
(1)字节操作流:OutputStream、InputStream
(2)字符操作流:Writer、Reader
一定要关闭操作的资源
OutputStream
// 实例,是否追加数据
public FileOutputStream(File file, boolean _append )
throws FileNotFoundException;
/** -------- 样例 ---------- **/
// 输出文件
File file = new File("D:"+File.separator + "demo"+ File.separator + "test.txt");
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
OutputStream output = new FileOutputStream(file);
String data = "hello world";
output.write(data.getBytes());
output.close();InputStream
// new InputStream实现类
public FileInputStream(File file) throws FileNotFoundException;
// 读取单字节
public abstract int read() throws IOException;
// 读取的数据保存到字节数组,读取完则返回-1
public int read(byte[] b) throws IOException;
/** -------- 样例 ---------- **/
//一次取出的字节数大小,缓冲区大小
byte[] buffer=new byte[512];
int numberRead=0;
InputStream input=null;
OutputStream out =null;
try {
input = new FileInputStream("tiger.jpg");
// 如果文件不存在会自动创建
out = new FileOutputStream("tiger2.jpg");
//numberRead的目的在于防止最后一次读取的字节小于buffer长度,
while ((numberRead=input.read(buffer))!=-1) {
out.write( buffer, 0, numberRead );
}
} catch (final IOException e) {
e.printStackTrace();
}finally{
try {
input.close();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
} 字符流
Writer
抽象类,实现类FileWriter,直接使用String型数据输出,不再需要将其变为字节数组
Writer out = new FileWriter(file);
public void write(String str) throws IOException;
out.flush() ; // 清空缓冲区BufferReader
BufferedWriter writer = new BufferedWriter( new FileWriter(name1 );
BufferedReader reader = new BufferedReader( new FileReader(name2) );
while ( ( str = reader.readLine() ) != null ) {
writer.write(str);
writer.newLine();
} Reader
Reader in = new FileReader(file);
public int read (char[] cbuf) throws IOException;
int len = in.read(data); // 读取数据
in.close();对比
不管文件读写还是网络发送接收,最小单元都是字节。
字符流是JAVA虚拟机将字节转换得到,很耗时,容易因为编码类型乱码。
字节流针对数据终端(文件),字符流针对缓存区(内存),通过缓存操作文件
使用字节流不关闭最后的输出流操作,也可以将所有内容输出
使用字符输出流不关闭,缓冲区内容不会被输出,可以调用flush()方法清空
实战
读取到字符串
/**
* 将文本文件转Str
* @param filePath 文件路径
* @return 文件字符串
* @throws Exception 所有异常
*/
public static String loadFile2Str(String filePath) throws Exception {
File file = new File(filePath);
FileReader reader = new FileReader(file);
BufferedReader bReader = new BufferedReader(reader);
StringBuilder sb = new StringBuilder();
String s = "";
while ( (s = bReader.readLine() ) != null ) {
sb.append(s).append("\n");
}
bReader.close();
reader.close();
return sb.toString();
}移动 & 复制
public static boolean fileMove(String originPath, String nowPath) {
File oldFile = new File(originPath);
File newFile = new File(nowPath);
return oldFile.renameTo(newFile);
}
public static void fileCopy(String srcPathStr, String desPathStr)
{
try
{
FileInputStream fis = new FileInputStream(srcPathStr);
FileOutputStream fos = new FileOutputStream(desPathStr);
byte[] datas = new byte[1024*8];
int len = 0;
while((len = fis.read(datas))!=-1)
{
fos.write(datas,0,len);
}
fis.close();
fos.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}拷贝
public static void main(String[] args) throws Exception {
File inFile = new File("D:" + File.separator + "demo"
+ File.separator + "test.zip"); // 定义文件路径
File outFile = new File("D:" + File.separator + "demo"
+ File.separator + "test2.zip"); // 定义文件路径
long start = System.currentTimeMillis();
if (!inFile.exists()) { // 源文件不存在
System.out.println("源文件不存在!");
System.exit(1); // 程序退出
}
if(!outFile.getParentFile().exists()){
outFile.getParentFile().mkdirs();
}
InputStream input = new FileInputStream(inFile);
OutputStream output = new FileOutputStream(outFile);
int temp = 0;//保存每次读取的个数
byte data[] = new byte[4096]; // 每次读取4096字节
while ((temp = input.read(data)) != -1) { // 将每次读取进来的数据保存在字节数组里,并返回读取的个数
output.write(data, 0, temp); // 输出数组
}
long end = System.currentTimeMillis();
System.out.println("拷贝完成,所花费的时间:" + (end - start) + "毫秒");
input.close();
output.close();
}文件夹列表
/**
* 从目录中BFS获取所有文件加入MAP
* @param path 目录路径
* @param fileMap 将加入的map String fileName, String filePath
* @return fileMap String fileName, String filePath
*/
public static Map<String, String> findAllFile2Map(String path, Map<String, String> fileMap) {
// bfs 加载所有文件进入Map<String fileName, String path>
Queue<File> dirQueue = new LinkedList<>();
// 获得指定文件对象
File file = new File(path);
dirQueue.offer(file);
// bfs 获取所有文件夹和文件
while(dirQueue.size() != 0) {
file = dirQueue.poll();
// 目录加入队列
if (file.isDirectory()) {
File[] files = file.listFiles();
if (files != null && files.length != 0) {
for (File nowFile : files) {
dirQueue.offer(nowFile);
}
}
// 文件加入Map
} else {
fileMap.put(file.getName(), file.getAbsolutePath());
}
}
// 遍历Map的文件,正则匹配的文件移动到res文件夹
return fileMap;
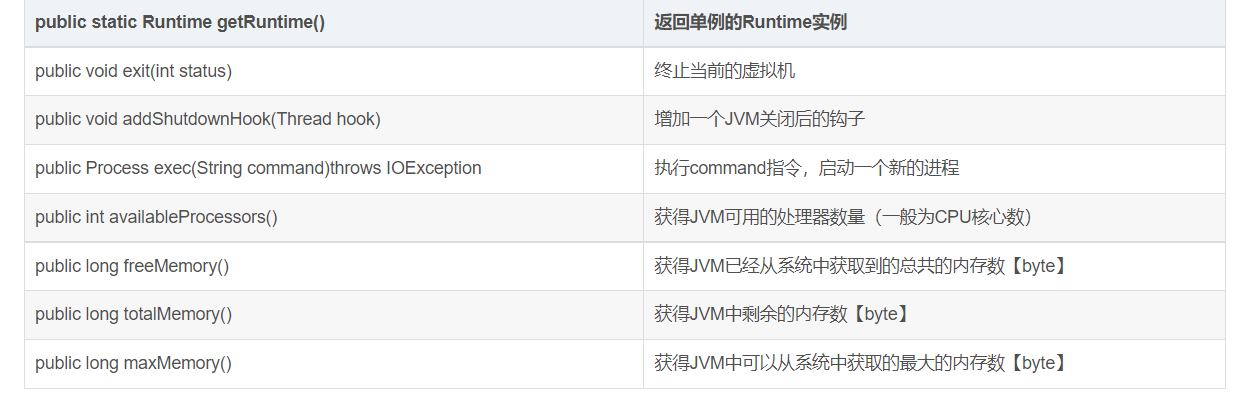
}Runtime
- 执行一个进程。
- 调用垃圾回收。
- 查看总内存和剩余内存。
新特性
Optional
防止 NullPointerException (NPE)的漂亮工具
详细:https://blog.kaaass.net/archives/764
// of():为非null的值创建一个Optional,如果是null会报错
Optional<String> optional = Optional.of("bam");
// isPresent(): 如果值存在返回true,否则返回false
optional.isPresent(); // true
// ifPresent():如果Optional实例有值则为其调用consumer,否则不做处理
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
// get():如果Optional有值则将其返回,否则抛出NoSuchElementException
optional.get(); // "bam"
// orElse():如果有值则将其返回,否则返回指定的其它值
optional.orElse("fallback"); // "bam"
// orElseGet()
optional.orElseGet(() -> method());
User u;
Optional.ofNullable(u)
.map(user->user.name)
.orElse("Unknown");
public static String getChampionName(Competition comp) throws IllegalArgumentException {
return Optional.ofNullable(comp)
.map(Competition::getResult) // 相当于c -> c.getResult(),下同
.map(CompResult::getChampion)
.map(User::getName)
.orElseThrow(()->new IllegalArgumentException("The value of param comp isn't available."));
}Stream
peek没有返回值,map有返回值
stream().filter()只保留true的
List<Integer> transactionsIds =
widgets.stream()
.filter(b -> b.getColor() == RED)
.sorted((x,y) -> x.getWeight() - y.getWeight())
.mapToInt(Widget::getWeight)
.sum();获取
- stream() − 为集合创建串行流。
- parallelStream() − 为集合创建并行流。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());filter
stream().filter()只保留true的
foreach
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);map
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
// 获取对应的平方数
List<Integer> squaresList =
numbers
.stream()
.map( i -> i*i)
.distinct()
.collect(Collectors.toList());peek
// 没有返回值,修改了age
studentList.stream()
.peek(o -> o.setAge(100))
.forEach(System.out::println); Reduce
//测试 Reduce (规约)操作
Optional<String> reduced =
stringList
.stream()
.sorted()
// s1 是以前处理的整合,s2是现在的
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println); //aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F")
.filter(x -> x.compareTo("Z") > 0)
.reduce("", String::concat);flatMap
流中的值换成另一个流,返回流,汇合流
List<String> list = Arrays.asList("a,b,c", "1,2,3");
Stream<String> s3 = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
});
s3.forEach(System.out::println); // a b c 1 2 3limit
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);sort
需要自定义 Comparator ,否则会使用默认排序
Random random = new Random();
random.ints().limit(10).sorted().forEach(System.out::println);
studentList.stream().sorted(
(o1, o2) -> {
if (o1.getName().equals(o2.getName())) {
return o1.getAge() - o2.getAge();
} else {
return o1.getName().compareTo(o2.getName());
}
}
).forEach(System.out::println);
// 测试 Map 操作
stringList
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a)) // 降序
.forEach(System.out::println);// "DDD2", "DDD1"Match匹配
检测指定的Predicate是否匹配整个Stream
// 1.anyMatch 任意一个
// 2.allMatch 都符合
// 3.noneMatch 都不符合
// 测试 Match (匹配)操作
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true
boolean allMatch = list.stream().allMatch(e -> e > 10); //false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); //trueParallel Streams
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 获取空字符串的数量
long count = strings.parallelStream().filter(string -> string.isEmpty()).count();统计
count:返回流中元素的总个数
max:返回流中元素最大值
min:返回流中元素最小值
long count = list.stream().count(); //5
Integer max = list.stream().max(Integer::compareTo).get(); //5
Integer min = list.stream().min(Integer::compareTo).get(); //1IntSummaryStatistics
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
IntSummaryStatistics stats = numbers
.stream()
.mapToInt((x) -> x)
.summaryStatistics();
System.out.println("列表中最大的数 : " + stats.getMax());
System.out.println("列表中最小的数 : " + stats.getMin());
System.out.println("所有数之和 : " + stats.getSum());
System.out.println("平均数 : " + stats.getAverage());获取元素
findFirst:返回流中第一个元素
findAny:返回流中的任意元素
需要使用isPresent()判断是否空
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
if (list.stream().findFirst().isPresent() && list.stream().findAny().isPresent()) {
Integer findFirst = list.stream().findFirst().get(); //1
Integer findAny = list.stream().findAny().get(); //1
}常见错误
Collectors.toMap
Collectors.toMap的坑,需要考虑是否能有重复key,以及是值为空的判断
- 坑1,重复key,IllegalStateException
- 坑2,值为null,NullPointerException
// 1. 简单判空
studentDTOS.stream().collect(
Collectors.toMap(
StudentDTO::getStudentId,
studentDTO -> studentDTO.getStudentName() == null ? "" : studentDTO.getStudentName(),
(oldValue, newValue) -> oldValue
)
);
// 2. 其他的collect方式【最佳】,能解决值重复和null
Map<Integer, String> collect = studentDTOS.stream().collect(
HashMap::new,
(n, v) -> n.put(v.getStudentId(), v.getStudentName()),
HashMap::putAll
);
// 3. Optional封装
Map<Integer, Optional<String>> collect = studentDTOS.stream().collect(
Collectors.toMap(
StudentDTO::getStudentId,
studentDTO -> Optional.ofNullable(studentDTO.getStudentName()).orElse(""),
(oldValue, newValue) -> oldValue
)
);注解与反射
注解
内置注解
- @Override: 重写父类方法
- @Deprecated: 不推荐使用
- @SuppressWarnings: 抑制编译时的警告信息 @SuppressWarnings(“all”)
元注解

自定义注解
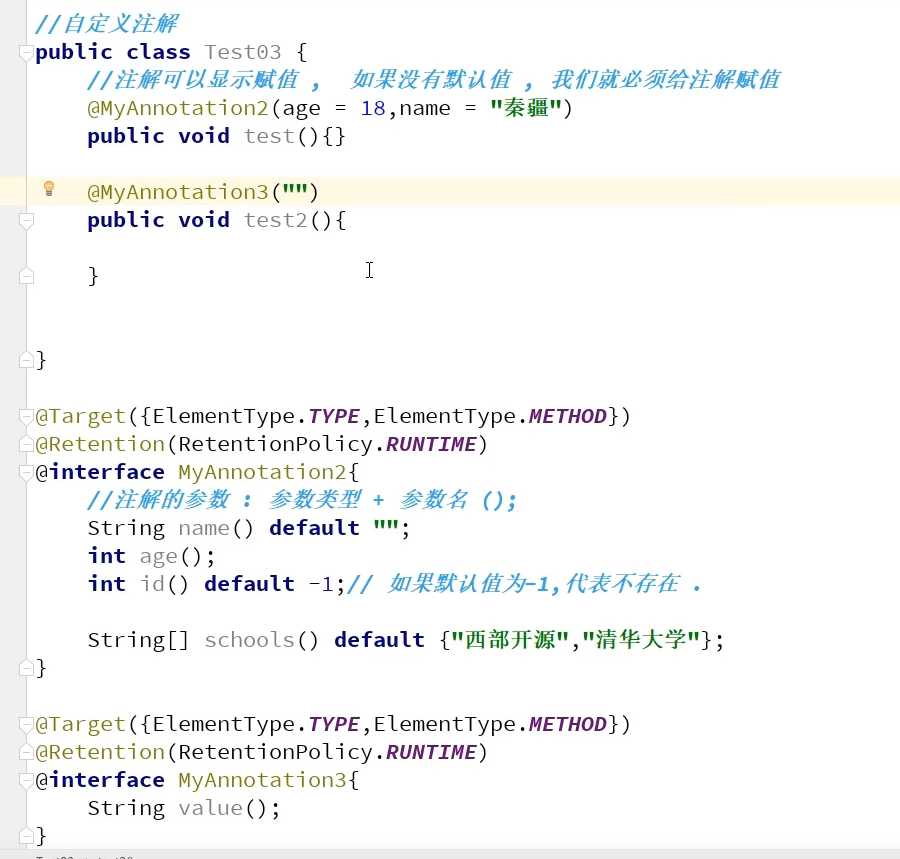
@MyAnnotation(age=18, name="mingming")
public void test(){
}
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotation{
String name() default "";
int age();
int id() default -1; //默认不存在
String[] schools() default {"清华", "北大"};
}反射
动态语言:在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。通俗点说就是在运行时代码可以根据某些条件改变自身结构。
java能够通过反射动态改变
好处:
- 提高了程序的灵活性和扩展性,降低耦合性,提高自适应能力,无需提前硬编码目标类
缺点
- 性能差
- 模糊内部逻辑,比直接代码复杂
静态、动态


一个类只有一个Class对象,类被加载后,类的整个结构都封装在Class对象中
获取class类


创建对象
创建
创建类的对象:调用Class对象的newInstance()方法
- 类必须有无参构造器
- 类的构造器访问权限足够

public static void main(){
//1.获取class对象
Class c1 = class.forName("con.ming.reflection.User");
//2.构建对象
//2.1无参
User user = (User)c1.newInstance();//使用无参数构造器
/**
* java9
* c1.getDeclaredConstructor().newInstance();
**/
//2.2通过构造器创建对象
Constructor constructor = c1.getDeclaredContructor(String.class, int.class, int.class);
User user2 = constructor.newInstance("名", 001, 18);
}普通方法
获取方法:
Method setName = c1.getDeclaredMethod(“setName”, String.class);
调用方法:
setName.invoke(user3, “ming”);
User user3 = (User)c1.newInstance(); Method setName = c1. getDeclaredMethod("setName", String.class); //方法名,参数 setName.invoke(user3, "mingming");
操作属性:
User user4 = (User)c1.newInstance(); Field name = c1.getDeclaredField("name"); //name.setAccessible(ture); 允许访问private,提高效率 name.set(user4, "明明"); //无法使用privatesetAccessible 允许访问private
性能
User user = new User(); /** * 反射 * Class c1 = user.getClass(); * Method getName = c1.getDeclaredMethod("getName", null); * getName.setAccessible(true); **/ long startTime = System.currentTimeMillis(); for(int i = 0; i < 1000000000; i++ ){ user.getName(); /** * getName.invoke(user, null); **/ } long endTime = System.currentTimeMillis();
```
- 普通方法9ms
- 反射5000ms
- 关闭检测(允许访问) 2000ms操作泛型

获取泛型

public void test01(Map<String,User> map, list<User> list){
}
public Map<String, User> test(){
}
public main(){
}操作注解
ORM
- 对象关系映射
- 类和表结构对应
- 属性和字端对应
- 对象和记录对应
反射操作注解
@TableMing("db_student")
Class Student{
@FieldMing(columnName = "db_id", type = "int", length = 10)
private int id;
@FieldMing(columnName = "db_age", type = "int", length = 10)
private int age;
3 @FieldMing(columnName = "db_name", type = "varchar", length = 10)
private String name;
/*get set*/
}
@tableMing("db_student")
class student2{}
//类名注解
@Target(ElementType.Type) //作用在type上
@Retnetion(RetentionPolicy.RUNTIME) //在runtime可以获取
@interface TableMing{
String value();
}
//属性的注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@interface FieldMing{
String columnName(); //类名
String type(); //参数类型
int length();
}
public void test(){
Class c1 = Class.forName("com.ming.reflection.Student");
//通过反射获取注解
Annotation[] annotation = c1.getAnnotations();
for(Annotation annotation : annotations){
sout(annotation);
}
//获取注解的value的值
TableMing TableMing = (TableMing)c1.getAnnotation(TableMing.class);
String value = tableMing.value();
sout(value);
//获取类指定的注解
Field f = c1.getDeclaredFiled("name");
FieldMing annotation = f.getAnnotation(FieldMing.class);
sout(annotaion.columnName());
}propertyDescriptor
JavaBean 类通过存储器导出一个属性(即使没有get、set方法也能使用),能够使用其修改其get、set方法,但是直接调用默认的get、set不会改变
构造方法:
PropertyDescriptor(String propertyName, Class<?> beanClass)
PropertyDescriptor(String propertyName, Class<?> beanClass, String readMethodName, String writeMethodName)
PropertyDescriptor(String propertyName, Method readMethod, Method writeMethod)常用方法
// 获取属性的java类型对象
Class<?> getPropertyType()
// 获得用于读取属性值的方法
Method getReadMethod()
// 获得用于写入属性值的方法
Method getWriteMethod()
// Sets the method that should be used to read the property value.
void setReadMethod(Method readMethod)
//Sets the method that should be used to write the property value.
void setWriteMethod(Method writeMethod) 样例
person类
package com.cwind.property;
public class Person {
private String name ;
private int age ;
public Person(){ this.name = ""; this.age = 0; }
public Person(String name, int age) { super(); this.name = name; this. age = age; }
public String getName() { return name; }
public void setName(String name) { this. name = name; }
public int getAge() { return age; }
public void setAge(int age) { this. age = age; }
public String getNameInUpperCase(){
return this.name.toUpperCase();
}
public void setNameToLowerCase(String name){
this.name = name.toLowerCase();
}
} 使用
Class personClass = Class.forName("com.cwind.property.Person");
// 然后可以通过两种方式构造PropertyDescriptor
// 1.获取name的属性描述器,使用其标准getter和setter
PropertyDescriptor prop1 = new PropertyDescriptor( "name", Person.class );
// 2.使用其他方法覆盖原来的get、set
Method read = personClass.getMethod("getNameInUpperCase", null);
Method write = personClass.getMethod("setNameToLowerCase", String.class );
// 使用read和write两个方法对象,覆盖所自定义的getter和setter
PropertyDescriptor prop2 = new PropertyDescriptor( "name", read, write);
// 下面构建一个Person对象 name, age
Person person = new Person("Kobe" , 36);
// 获取值
// 实际调用Person.getName(), result: Kobe
prop1.getReadMethod().invoke(person, null);
// 实际调用Person.getNameInUpperCase(), result: KOBE
prop2.getReadMethod().invoke(person, null);
// 修改值
// 实际调用Person.setName(), person.name被设置为James
prop1.getWriteMethod().invoke(person, "James");
// 实际调用Person.setNameToLowerCase(), person.name被设置为james
prop2.getWriteMethod().invoke(person, "James"); 实例
// spring,好像加了缓存
PropertyDescriptor sourceDescriptor = BeanUtils.getPropertyDescriptor(context.getRequest().getClass(), "acco");
Method writeMethod = sourceDescriptor.getWriteMethod();
writeMethod.invoke(object, param);总结
注解
什么是注解annotation
@
可以被其他程序(编译器等)读取
可以使用在package,class,method,field,给额外的负责信息,可以通过反射机制变成设置对这些元数据的访问
内置注解
@Override 该方法重写父类方法
@Deprecated 不鼓励使用该方法
@SuppressWarnings(“all”) 抑制编译警告信息
(“unchecked”) (value={“unchecked”, “deprecation”})
自定义注解
@Target 描述该注解使用范围
@Rentention 描述声明周期(SOURCE<CLASS<RUNTIME)
@Document 说明注解包含在javadoc中
@Inherited 可以继承该注解
反射
静态、动态
动态语言,类在运行时可以改变其结构
什么是反射
Reflection是java被视为动态语言的关键,反射机制允许程序在执行期间借助-ReflectionAPI取得任何类的内部信息,并能直接操作任意对象的内部属性和方法
- Class c = Class.forName(“java.lang.String”);
加载完类后,在堆内存的方法去中产生了Class类型的对象(一个类只有一个Class对象),这个对象包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。

反射的API
- java.lang.Class 代表一个类
- java.lang.reflect.Method 类的方法
- .Field 类的成员变量
- .Constructor 类的构造器
Class类的常用方法

获取Class类实例
Class class = Person.class
Class class = person.getClass();
Class class = Class.forName(“domo.Student”)
异常
异常类关系

类区分
Error和Exception
Error是编译时错误和系统错误
Exception则是可以被抛出的基本类型,常见编码运行时错误
RunTimeException和其他
其他Exception(InterupteException、IOException),受检查异常。必须解决编译通过,解决的方法有两种,
1:throw到上层,
2:try-catch处理。
RunTimeException:运行时异常,因为不受检查在实际运行代码时则会暴露出来,比如经典的1/0,空指针等,如果不处理也会被Java自己处理。
@SneakyThrows
来源:https://blog.csdn.net/qq_22162093/article/details/115486647
处理其他Exception(InterupteException、IOException)时
通常是
try {
} catch (Exception e) {
throw new RuntimeException(e);
}使用
import lombok.SneakyThrows;
public class SneakyThrowsExample implements Runnable {
@SneakyThrows(UnsupportedEncodingException.class)
public String utf8ToString(byte[] bytes) {
return new String(bytes, "UTF-8");
}
@SneakyThrows
public void run() {
throw new Throwable();
}
}
编译后会自动throw catch,throw
import lombok.Lombok;
public class SneakyThrowsExample implements Runnable {
public String utf8ToString(byte[] bytes) {
try {
return new String(bytes, "UTF-8");
} catch (UnsupportedEncodingException e) {
throw Lombok.sneakyThrow(e);
}
}
public void run() {
try {
throw new Throwable();
} catch (Throwable t) {
throw Lombok.sneakyThrow(t);
}
}
}
原理
利用泛型将我们传入的Throwable强转为RuntimeException
public static RuntimeException sneakyThrow(Throwable t) {
if (t == null) throw new NullPointerException("t");
return Lombok.<RuntimeException>sneakyThrow0(t);
}
private static <T extends Throwable> T sneakyThrow0(Throwable t) throws T {
throw (T)t;
}其他
DecimalFormate格式化数据
原文:https://www.jianshu.com/p/c1dec1796062
需要将一个数值转换为格式化的数值,比:3.145678保留两位有效数字
占位符
我们要实现格式化数据,需要使用到DecimalFormat的其中一个构造方法:
public DecimalFormat(String pattern)构造参数pattern就是用来格式化的:一个非本地化的模式字符串。
0和#都是常用的占位符,但是他们俩还有些区别。
0补位
#不补位
舍入方式
当要格式化的数字超过占位符的时候,格式化的结果会进行四舍五入。这并不是按照四舍五入的方式舍入的,而是因为没有指定格式化的RoundingMode,而默认使用了RoundingMode.HALF_EVEN方式。
使用方式
下面举两个例子,指定舍入方式的格式化。
DecimalFormat format = new DecimalFormat("#.##");
//指定舍入方式为:RoundingMode.DOWN,直接舍去格式化以外的部分
format.setRoundingMode(RoundingMode.DOWN);
String formatDown = format.format(13.14567);//结果:13.14
//指定舍入方式为:RoundingMode.HALF_UP,四舍五入
format.setRoundingMode(RoundingMode.HALF_UP);
String formatHalfUp = format.format(13.14567);//结果:13.15总结
关于DecimalFormat 的舍入方式,可以参考以上的例子,根据需求的不同,使用对应的RoundingMode。
封装
下面是个例子来实现String类型的格式化,将String类型的数据,格式化为只保留有效数字,最多保留两位小数,采用截取方式的方法(这个方法返回的是double,至于返回String、float、int都是可以的)。
/**
* @param str 需要格式化的字符串
* @return 格式化后的double型数值
*/
public static double stringToDouble(String str) {
if (TextUtils.isEmpty(str)) {
return 0;
}
DecimalFormat format = new DecimalFormat("#.##");
//提供 RoundingMode 中定义的舍入模式进行格式化。默认情况下,它使用 RoundingMode.HALF_EVEN。
format.setRoundingMode(RoundingMode.DOWN);
//使用BigDecimal对象来将String类型转换为DecimalFormat可以格式化的类型。
String formatStr = format.format(new BigDecimal(str));
//将格式化后的类型,转换为double类型(当然,也可以转换为float或int,视需求而定)。
BigDecimal bigDecimal = new BigDecimal(formatStr);
return bigDecimal.doubleValue();
}日期
Date time = new Date(121, Calendar.AUGUST, 18);
time.setHours(10);
long days = DateUtil.betweenDay(time, new Date(), true); // 忽略小时 hutool算法
输入输出
输入
Scanner s = new Scanner(System.in)
| 方法 | 描述 |
|---|---|
| String next() | 接受的字符串以空格划分且不包含\n |
| String nextLine() | 接收的字符串以行划分且包含\n |
| int nextInt() | 接收一个整型值以空格划分 |
有大量输入数据时,使用BufferedReader reader = new BufferedReader(new InputSreamReader(System.in));
输出
System.out.println()-—-当输出大量数据的时候效率很低BufferedWriter log = new BufferedWriter(new OutputStreamWriter(System.out));
使用log.write();-—-输出大量数据的时候效率更高,不过需要捕获异常,还需要注意:只能输出字符数组和字符串,如果单独输出整型的话,相对于输出的是对应该整型ASCII码的字符,最后flush()一下,否则不会输出
大量输入数据和输出数据案例
BufferedWriter
write方法只能输出单个字符或字符串而且不换行
如果需要输出整型值,可以根据题目输出条件,在整型值后面 + “ “ 或 “\n”,就转为字符串了
最后在程序结束前flush()
BufferedReade
- readLine方法配合String类的spilt方法使用
- 把每一行当作一次输入就行
- 注意用Integer.parseInt()把字符串转为整型
排序
https://www.cnblogs.com/onepixel/articles/7674659.html
查找
二分
- ( min + max ) / 2取中间下标
- 与中间值比较
- 中间值较大, max = mid - 1
- 中间值较小, min = mid + 1
- 相等, return mid
- 循环条件为 min <= max
class Solution {
public int search(int[] nums, int target) {
return Solution.binarySearch(nums, target);
}
private static int binarySearch(int[] arr, int searchValue) {
int maxIndex = arr.length - 1,
minIndex = 0,
midIndex = 0;
// 获取中间值
while( minIndex <= maxIndex) { // 没找到,并且还有能找
midIndex = ( minIndex + maxIndex ) / 2;
if( arr[midIndex] == searchValue ) { // 1.相等,结束
return midIndex;
} else if( arr[midIndex] < searchValue ) { // 2.中间值太小,取右侧
minIndex = midIndex + 1;
} else if( arr[midIndex] > searchValue) { // 3.中间值太大,取左侧
maxIndex = midIndex - 1;
}
}
return -1;
}
}正则
正则匹配工具:https://tool.chinaz.com/regex/
正则状态机:https://regexper.com/
API
Pattern类:正则表达式的编译表示
Matcher类:对输入的字符串进行解释和匹配操作
String pattern = "(\\D*)(\\d+)(.*)";
// 1 使用
boolean Pattern.matches(pattern, content);
// 2 使用
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(content);
boolean m.find();
m.group(0); // 整组 (\\D*)(\\d+)(.*)
m.group(1); // 组内的匹配的元素 (\\D*)Matcher
/** ------ 查找 -------**/
// 从起始位置查找
public boolean lookingAt();
// 查找当前字符串匹配的第一个匹配序列,会排除已经匹配的
public boolean find();
// 指定索引开始找
public boolean find(int start);
// find 之后 [ , )
matcher.start(); matcher.end();
// 要整个字符串匹配
public boolean matches();
// 重置字符串
matcher.reset();
/** ------ 索引 ------ **/
// 匹配的初始索引
public int start();
// 匹配组的初始索引
public int start(int group);
// 最后匹配字符之后的偏移量
public int end();
public int end(int group);
/** ------ 替换 ------ **/
m.replaceFirst("new");
m.replaceAll("new");
// 替换匹配的
while( m.find() ){
m.appendReplacement(sb,REPLACE);
}
// 输入序列的字符附加到该对象
m.appendTail(stringBuffer);
特殊符号
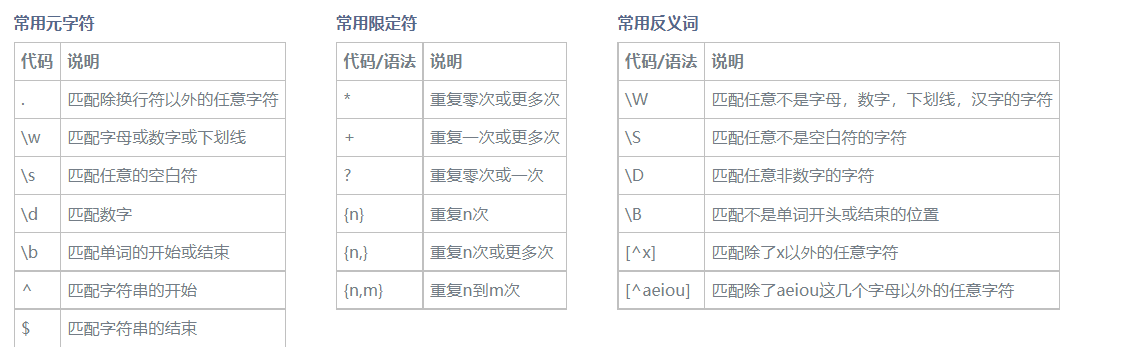
? 0或者1次,* 0或者无数次,+一次或无数次,{min, max}
| 匹配区间 | 正则表达式 | 记忆方式 |
|---|---|---|
| 除了换行符之外的任何字符 | . | 句号,除了句子结束符 |
| 单个数字, [0-9] | \d | digit |
| 除了[0-9] | \D | not digit |
| 包括下划线在内的单个字符,[A-Za-z0-9_] | \w | word |
| 非单字字符 | \W | not word |
| 匹配空白字符,包括空格、制表符、换页符和换行符 | \s | space |
| 匹配非空白字符 | \S | not space |
| 特殊字符 | 正则表达式 | 记忆方式 |
|---|---|---|
| 换行符 | \n | new line |
| 换页符 | \f | form feed |
| 回车符 | \r | return |
| 空白符 | \s | space |
| 制表符 | \t | tab |
| 垂直制表符 | \v | vertical tab |
| 回退符 | [\b] | backspace,之所以使用[]符号是避免和\b重复 |
边界
/^I am scq000\.$/m
| 边界和标志 | 正则表达式 | 记忆方式 |
|---|---|---|
| 单词边界 | \b | boundary |
| 非单词边界 | \B | not boundary |
| 字符串开头 | ^ | 小头尖尖那么大个 |
| 字符串结尾 | $ | 终结者,美国科幻电影,美元符$ |
| 多行模式 | m标志 | multiple of lines |
| 忽略大小写 | i标志 | ignore case, case-insensitive |
| 全局模式 | g标志 | global |
组
| 回溯查找 | 正则 | 记忆方式 |
|---|---|---|
| 引用 | \0,\1,\2 和 $0, $1, $2 | 转义+数字 |
| 非捕获组 | (?:) | 引用表达式(()), 本身不被消费(?),引用(:) |
| 前向查找 | (?=) | 限制后缀,引用子表达式(()),本身不被消费(?), 正向的查找(=) |
| 前向负查找 | (?!) | 限制后缀不拥有/happ(?!ily)/匹配到happy的happ,引用子表达式(()),本身不被消费(?), 负向的查找(!) |
| 后向查找 | (?<=) | 限制前缀,引用子表达式(()),本身不被消费(?), 后向的(<,开口往后),正的查找(=) |
| 后向负查找 | (?<!) | 限制前缀不拥有,引用子表达式(()),本身不被消费(?), 后向的(<,开口往后),负的查找(!) |
逻辑处理
| 逻辑关系 | 正则元字符 |
|---|---|
| 与 | 无 |
| 非 | [^regex]和! |
| 或 | | |
常用正则
数字
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9″*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
字符
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\”等字符:[^%&',;=?$\x22]+
禁止输入含有的字符:`[^\x22]+`
特殊需求
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码(“XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX):^($$\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
身份证号(15位、18位数字):^\d{15}|\d{18}$
短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
IP地址:((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))\.){3}\2
钱
有四种钱的表示形式我们可以接受:”10000.00″ 和 “10,000.00″, 和没有 “分” 的 “10000″ 和 “10,000″:^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符”0″不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以”10.”是不通过的,但是 “10″ 和 “10.2″ 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数。下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
编程概念
Object划分
公司划分:
- DO(Data Object) :此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
- DTO(Data Transfer Object) :数据传输对象, Service 或 Manager 向外传输的对象。
- BO(Business Object) :业务对象,由 Service 层输出的封装业务逻辑的对象。
- AO (Application Object) : 应用对象, 在 Web 层与 Service 层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
- VO(View Object) :显示层对象,通常是 Web 向模板渲染引擎层传输的对象。
- Query :数据查询对象,各层接收上层的查询请求。注意超过 2 个参数的查询封装,禁止使用 Map 类来传输。
https://blog.csdn.net/qq_32447321/article/details/53148092
1.entity字段必须和数据库字段一样
2.model,前端需要什么我们就给什么
3.domain很少用,代表一个对象模块
PO
(persistant object) 持久对象
通常对应数据模型 ( 数据库 ), 本身还有部分业务逻辑的处理。与数据库中的表相映射的 java 对象。
最简单的 PO 就是对应数据库中某个表中的一条记录,多个记录可以用 PO 的集合。 PO 中应该不包含任何对数据库的操作。
DO
(Domain Object)领域对象
就是从现实世界中抽象出来的有形或无形的业务实体。
TO
(Transfer Object) ,数据传输对象
在不同应用程序之间传输的对象,比如远程调用
DTO
(Data Transfer Object)数据传输对象
原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,
泛指用于展示层与服务层之间的数据传输对象。
VO
(value object) 值对象
通常用于业务层之间的数据传递,和 PO 一样也是仅仅包含数据而已。但应是抽象出的业务对象 , 可以和表对应 , 也可以不 , 这根据业务的需要
BO
(business object) 业务对象
封装业务逻辑的 java 对象 , 通过调用 DAO 方法 , 结合 PO,VO 进行业务操作。
主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。 比如一个简历,有教育经历、工作经历、社会关系等等。 我们可以把教育经历对应一个 PO ,工作经历对应一个 PO ,社会关系对应一个 PO 。 建立一个对应简历的 BO 对象处理简历,每个 BO 包含这些 PO 。 这样处理业务逻辑时,我们就可以针对 BO 去处理。
POJO
(plain ordinary java object) 简单无规则 java 对象
纯的传统意义的 java 对象。就是说在一些 Object/Relation Mapping 工具中,能够做到维护数据库表记录的 persisent object 完全是一个符合 Java Bean 规范的纯 Java 对象,没有增加别的属性和方法
DAO
(data access object) 数据访问对象
负责持久层的操作。为业务层提供接口。此对象用于访问数据库。通常和 PO 结合使用, DAO 中包含了各种数据库的操作方法。通过它的方法 , 结合 PO 对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合 VO, 提供数据库的 CRUD 操作.